
Remote sensing: The process of detecting and monitoring the physical characteristics of an area by…
Introducing Google Earth Engine
What is Google Earth Engine?
Google Earth Engine (GEE) is a cloud-based platform that allows scientists and researchers to access peta-bytes (1 peta-byte is a 1000 terabytes) of satellite imagery and geospatial data. It provides users with advanced geospatial analytical capabilities and the option to write their own personalized scripts and tools that are easily shared with others. You can upload and work with your own personal data or anyone else’s, with permission. This is all thanks to Google’s computational infrastructure.

There are four pillars that make GEE so high-calibre and superior to traditional desktop-based remote sensing analysis. These are:
- Data:
- Massive catalogue of remote sensing datasets, grows daily.
- Googles Computational Infrastructure:
- Large collection of servers, co-located with data.
- Allows for cloud-based parallel processing (one task split between many computers).
- API (Application Programming Interface):
- Straight-forward and effective Java-script and Python API.
- 3rd party integrations for other languages + software.
- Browser-based IDE (Integrated Development Environment):
- Entirely browser based – all that is required is an internet connection.
- The difference between traditional remote sensing analysis and GEE is similar to the change from physical DVD rental to Netflix. Instead of having to source somewhere to get the data, acquire/purchase the data, possess hardware to process the data, all you need is an internet connection.
What can it do?
As our planet faces increasing environmental concerns and threats to its wellbeing, desktop computing will no longer be adequate in visualising the true scale of these issues. Cloud-based computing like GEE allow for planet-wide analysis and could hold the key to solving humanities most important challenges. There is something very different about looking at detailed planet-wide datasets and I believe the more we use this software, the more we understand the Earth.
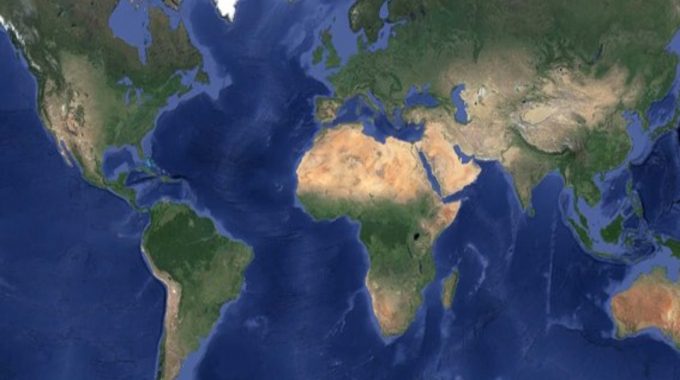
An example of a planet wide dataset that took advantage of GEEs processing power is the cloud-free composite of the entire Earth. This was made possible with GEE processing over 15tbs of satellite imagery and only accepting images with <2% cloud cover to be incorporated in the final composite.

While not an accurate representation of the Earth (this image represents springtime everywhere), it is a beautiful portrayal of our planet and went on to be used as Googles main satellite base map. It can also be used for large-scale land cover classification tasks.
Use Case Applications:
GEE can be manipulated for a wide variety of tasks due to its APIs being extensible and the ease at which one can make an interactive app within the code editor. An example of this is the Climate Engine. Climate Engine is based on the GEE platform but provides a convenient interface for users to pick and choose geospatial climate data to visualise within seconds. It has time-series mapping information included. This removes the programming aspect for scientists/researchers without coding experience. It enables you to share your research with others via a simple link.

Google Earth Engine for Machine Learning:
So, we now know why Google Earth Engine is so practical, removing the time-consuming task of downloading and processing data. However, the user-friendly IDE also makes running advanced computations like machine learning classifications that much easier for beginners. Within 30 lines of code one can write a basic machine learning script for land cover classification for a given area. For example, a basic supervised classification of the greatest city on Earth, Cork.
The first step is to label your training data. I assigned 4 different land cover classes, urban, water, vegetation, and bare earth. I labelled the training data on a composite I created from Sentinel-2’s 2019 data.


The model will later learn how to detect and differentiate the different land cover classes by the spectral reflectance of their pixels. For example, water has practically no Near-Infrared (NIR) and Intermediate-Infrared reflectance while vegetation has the highest NIR of all four classes.
Next, we must decide on a machine learning algorithm to implement. Google Earth Engine supports many different types but for the purpose of our classification, Random Forest is fitting.


As can be seen from our classification above, it is a good general representation of land cover in the area, however there are some inconsistencies. Yet for 15 minutes work, it is a good result. We can further improve our model by running accuracy assessments, adding normalized difference indexes or tuning the hyperparameters. The potential of Google Earth Engine is just being realised and we at Síor are keen explore this further.
Related Posts


Comments (0)